Projet Messenger
Introduction Link to heading
Meta (anciennement Facebook) a la fâcheuse tendance à sauvegarder bonne quantité de données qui lui tombe sous la dent. Heureusement, si vous vivez en Europe, certaines lois les contraignent, non pas à supprimer lesdites données, mais à vous les révéler.
J’ai donc décider de voir quelles données Facebook avait sur moi et j’ai réalisé sans grande surprise que la plateforme avait enregistré l’intégralité de toutes les conversations que j’ai pu avoir lors de mon utilisation du service. Ces données étaient donc, conformément à la loi, accessibles en de petits dossiers bien organisés.
J’ai donc décidé de m’amuser un peu avec ces informations et de voir ce qu’il était possible de faire.
J’écris cet article en 2025, mais j’ai réalisé ce projet en 2022, avant l’arrivée du chiffrement bout-à-bout et de la jointure avec les plateformes WhatsApp et Instagram. Certaines choses seront donc complètement différentes s’il fallait le refaire aujourd’hui. D’autant plus qu’il y a aujourd’hui le paquet PyPi: messenger-counter et le site doubletext.me (parmi d’autres) qui semblent réaliser plus ou moins la même tâche (même si je n’ai pas eu le temps de les essayer).
Les données Link to heading
Il s’agissait d’un gros fichier zip qui contient tout un tas de dossiers, pas si bien organisés que ça en réalité. Les conversations étaient sous la forme de fichier .json et étaient mélangées à des dossiers de photos ou de vidéos. Les longues conversations étaient divisées chronologiquement en plusieurs fichiers .json ce qui n’était pas pratique et a nécessité de les concaténer ensemble pour le traitement.
L’épuration des données Link to heading
Pour traiter les données brutes telles-quelles, j’ai commencé par définir le script data_cleaning.py qui enregistrait tous les utilisateurs ayant envoyé un message, et les regroupant dans un fichier .json à part. Ce traitement permettait aussi de convertir la date du format timestamp_ms à un format plus compréhensible : Jour Mois, Année - Heure:Minute:Seconde.
On se retrouve donc avec un fichier sous la forme:
[
{"name": "xxx xxx"},
{"name": "xxx xxx"},
{"name": "David Rillh"},
{"name": "xxx xxx"},
{"name": "xxx xxx"}
]
J’ai bien entendu pris soin d’anonymiser les noms de mes compagnons de conversations par respect pour leur (et ma) vie privée.
Certains types de donnée n’étaient pas vraiment exploitables en l’état et j’ai donc décidé de les supprimer car trop peu pratiques à utiliser. Il s’agissait principalement des appels audios ou vidéos ainsi que des pièces-jointes comme les images, vidéos ou enregistrements audio et enfin les sondages.
Pour des raisons inconnues il y avait beaucoup de dupliqués, des messages qui apparaissaient en deux fois. Heureusement il était plutôt facile de les filtrer pour diviser quasiment par deux le poids de notre tableau pandas (déjà très lourd).
Les fichiers .json suivent le format suivant :
[
{
"sender_id_INTERNAL": 0,
"sender_name": "David Rillh",
"content": "Quand est-ce que cette conv messenger a été créée ?",
"type": "Generic",
"is_unsent": false,
"is_taken_down": false,
"bumped_message_metadata": {
"bumped_message": "Quand est-ce que cette conv messenger a été créée ?",
"is_bumped": false
},
"datetime": "12 October, 2022 - 16:34:16"
},
,,,
]
Beaucoup de ces paramètres étaient toujours les mêmes au fil des messages, et avec du recul je ne vois même pas pourquoi je ne les ai pas supprimés. Il s’agissait de :
{
"sender_id_INTERNAL": 0,
"type": "Generic",
"is_unsent": false,
"is_taken_down": false,
"bumped_message_metadata": "<same message>",
"is_bumped": false
}
J’avais remarqué que ça aurait été très intéressant que is_unsent puisse avoir la valeur “true” puisque ça aurait voulu dire qu’il était possible de voir un message même après sa suppression. Il me semble avoir vérifié et avoir constaté que non, quand on supprime un message il n’apparaît pas non plus dans les données téléchargées.
Le traitement des données Link to heading
Pour traiter les données, j’ai utilisé la librairie pandas pour convertir toutes nos données en tableaux de données facilement exploitables. J’ai également utilisé matplotlib pour dessiner les graphs des différents résultats qui nous intéressent.
Pour traiter les données efficacement, mes mauvais réflexes de développeur m’ont fait partir dans tout plein de directions différentes, mais heureusement je me suis rappelé de l’OOP : Object-Oriented Programming.
J’ai donc écrit un fichier python dans lequel j’ai écrit tout un tas de fonctions python qui seront les briques du programme. Il y a, par exemple, la fonction simple qui compte le nombre de message par personne :
#This function is used to get the list of all participants
def get_participants(folder='.'):
...
#This function returns a pandas Series with the names and the total number of messages
def count_messages_per_person(df):
count = df['sender_name'].value_counts().sort_values()
count_df = pd.DataFrame({"sender_name": count.index, "message_count": count.values})
return count_df
Il me fallait également des fonctions pour gérer les graphs, qui allaient tous suivre une certaine template que j’ai donc défini en prenant compte des briques du dessus. Par exemple, le graph qui afficherait des barres horizontales :
# This function is used to plot the bar chart
def print_barh(people, values, title='', percentage=False, fsize=(20, 10)):
fig, ax = plt.subplots(figsize=fsize)
rects = ax.barh(people, values, color='orange')
ax.set_title(title)
rounded_values = [round(value, 2) for value in values]
if percentage == True:
rounded_values = [str(value) + '%' for value in rounded_values]
ax.bar_label(rects, rounded_values, padding=-50, color='white')
plt.show()
# A function that plots a series of values against a series of dates
def print_line(x, y, title='', xlabel='', ylabel='', fsize=(20, 10)):
...
Puis, j’ai défini une classe : Chat qui s’applique à chaque conversation et qui a des propriétés et des méthodes spécifiques utilisant les briques précédemment construites :
class Chat:
def __init__(self, folder='.'):
self.participants, self.messages = get_parti_msgs(folder)
self.count = count_messages_per_person(self.messages)
def show_count(self):
...
Les graphs et l’interprétation Link to heading
Maintenant que tout le boulot fastidieux est réalisé, on peut s’amuser !
J’ai été bien surpris de constater que j’étais celui de mon groupe d’ami qui avait envoyé le moins de messages !
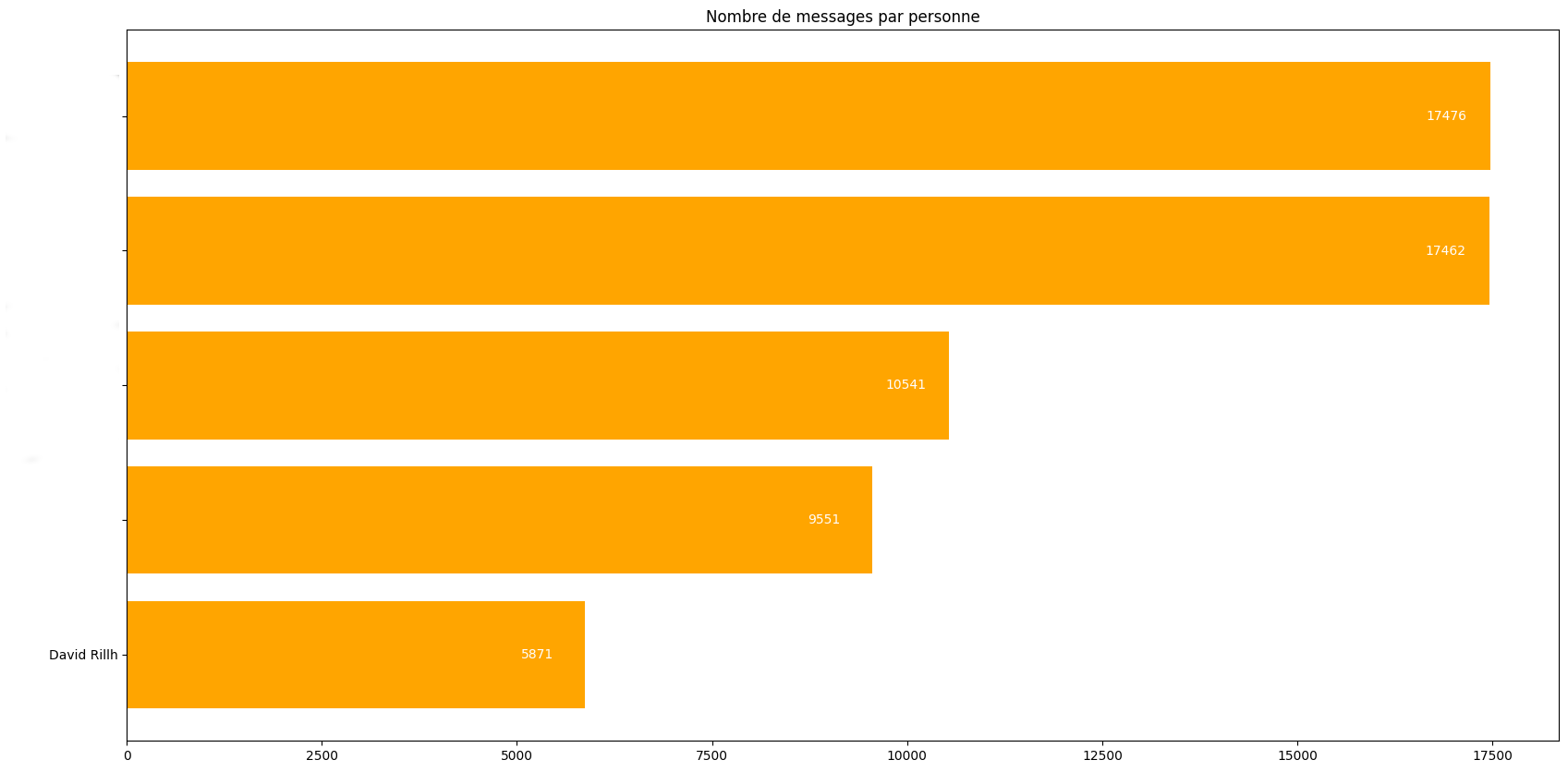
Les noms de mes amis sont effacés ici
Il y a de nombreux autres métriques qu’il est possible de réaliser grâce à ça maintenant :
-
Grapher le pourcentage de messages contenant certains mots comme “mdr”, “pourquoi”, “salut”, des caractères particuliers comme “?”, “:)”, “^^” ainsi que d’autres tics de language comme “mdr”, “jsp”, “pk” etc…
-
Grapher le nombre moyens de caractères par message
-
Grapher les mots les plus utilisés comme ci-dessous:
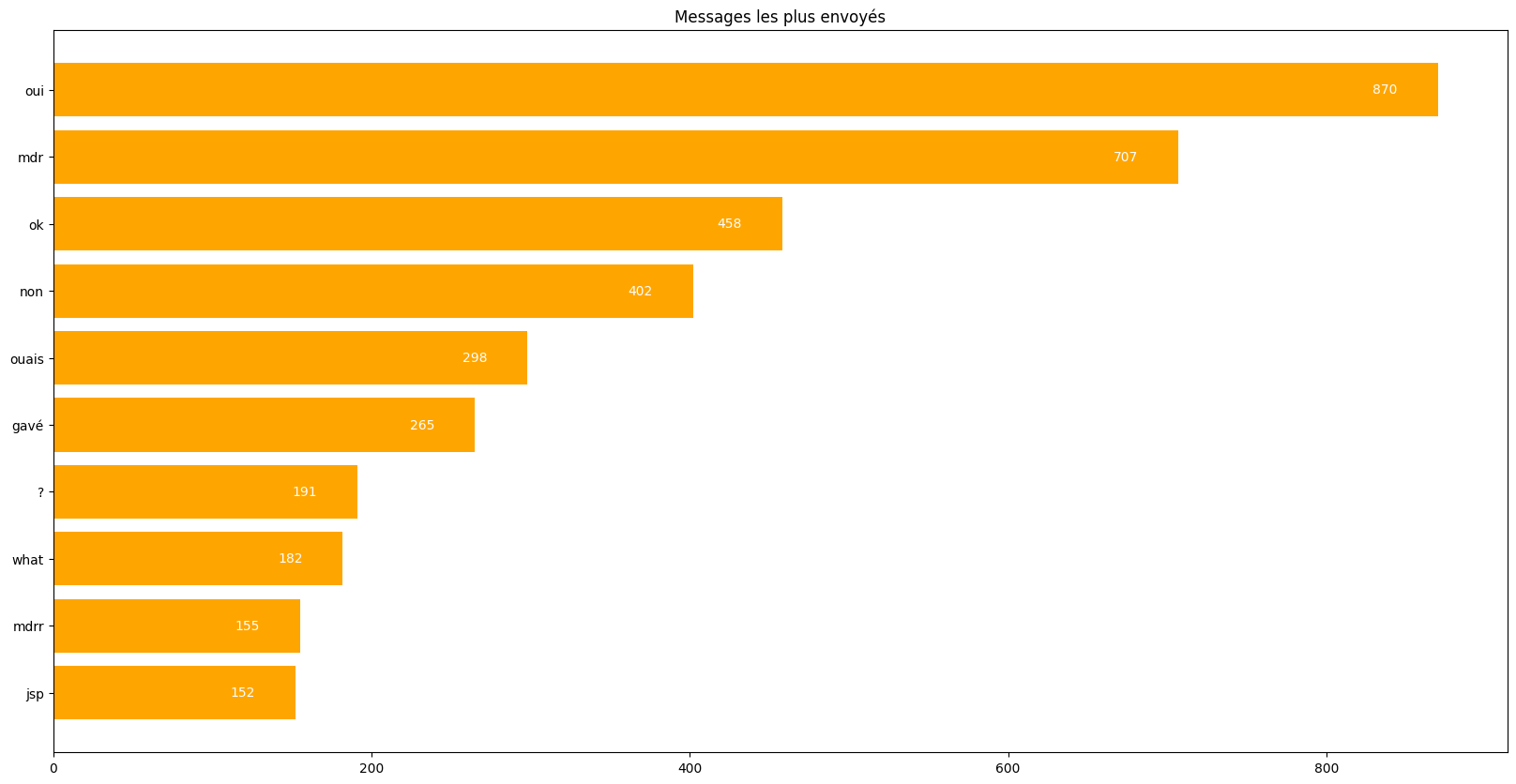
les mots les plus courts sont plus probables
-
Qui a le plus utilisé les mots les plus utilisés
-
Qui utilise le plus de mots liés à la nourriture ou à l’argent, qui est le plus poli (à utiliser des mots comme “svp”, “pardon”, “merci”, “de rien” etc…)
Ensuite, il peut être très intéressant de voir comment le nombre de messages par jour a évolué dans le temps. Pour cela on compte le nombre de messages par jour ou par mois ou par année, sur une période donnée :
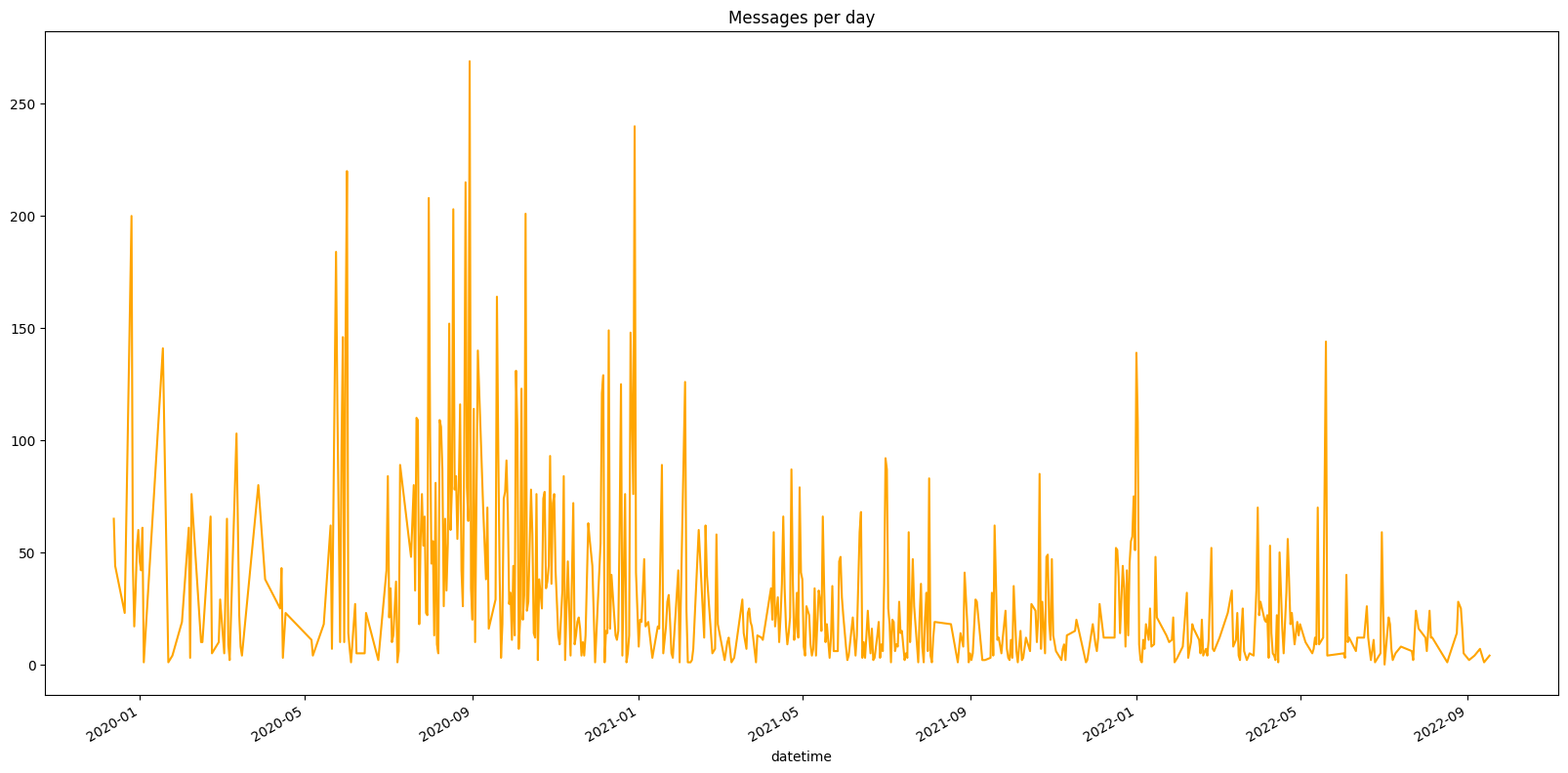
On peut voir se dégager des tendances
Plus de 250 messages en une journée ? Waouw je me demande ce qu’on a pu faire ce jour-là !
Il est aussi possible de voir la quantité de messages par jour qu’envoie juste une personne au fil du temps.
Conclusion Link to heading
Sans être trop rentré dans les détails du code ou de la conversation je pense que l’on a fait un bon tour d’horizon de ce projet et de comment le rendre amusant.
Si vous voulez aller plus loin vous pouvez consulter les ressources que j’ai déjà mentionnées mais sinon je vous invite à aller voir directement le projet sur GitHub !
À bientôt !